-
윈도우(Windows10-64bit) 환경에서 LLaMA(LLaMA-30b 4bit mode) 테스트하기<모델 로드까지>Dev LLM 2023. 3. 17. 21:36
며칠 전 리눅스에서 LLaMA-7B를 테스트해보고 이제는 로컬에서도 거대인공지능을 다룰 수 있다는 것을 알았다.
현재는 RTX3090을 쓸 수 있는 상황인데, 놀랍게도 GPTQ를 이용하면 메인스트림급으로 사용하는 RTX1660부터 LLaMA를 사용할 수 있다는 것을 알게 되었다. GPTQ는 GPTQ: Accurate Post-training Compression for Generative Pretrained Transformers란 논문 제목을 가지는데, GPT모델을 2/3/4비트로 압축하여 경량화하는 기술이다. 서핑하다 찾은 블로그의 표를 보면 RTX3090에서 기본 모델은 LLaMa-7b를 겨우 돌리나, GPTQ를 활용하면 더 좋은 성능의 LLaMa-30b까지 가능하다고 합니다.
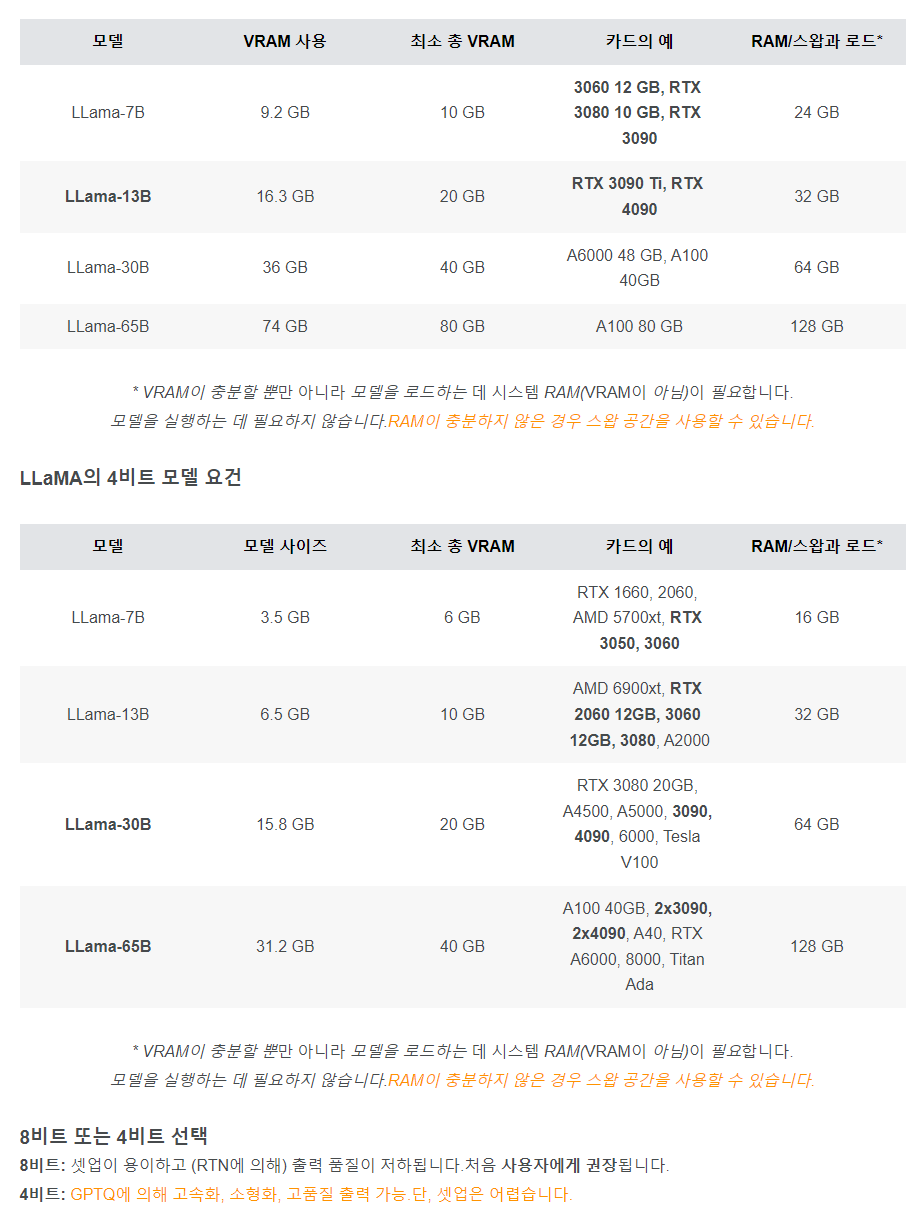
참조 https://blog.naver.com/carrier00/223042971354 Windows10-64bit에서 GPTQ를 활용한 LLaMa-30b(4bit mode) 테스트 과정을 정리합니다~
주요과정
1. 아나콘다 설치
2. 관련 종속프로그램 설치
3. 가상환경 구성
4. 파이토치, 쿠다환경구성
5. text-generation-webui 설치
6. GPTQ-for-LLaMa 설치
7. huggingface버전 model 다운로드
8. text-generation-webui 실행
세부과정
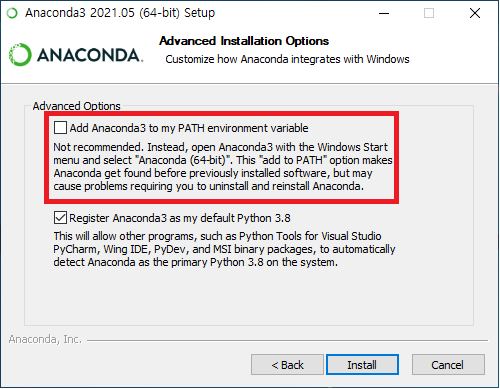
1. 아나콘다 설치 : 윈도우환경 Anaconda(아나콘다) 설치하기 같은 블로그를 참고하세요~
*설치 중 내 가상환경 환경변수 등록 체크하기, 안하심 아래 파이썬 실행 에러를 해결하면서 환경구성에 대해 좀 더 알게 되실 겁니다~
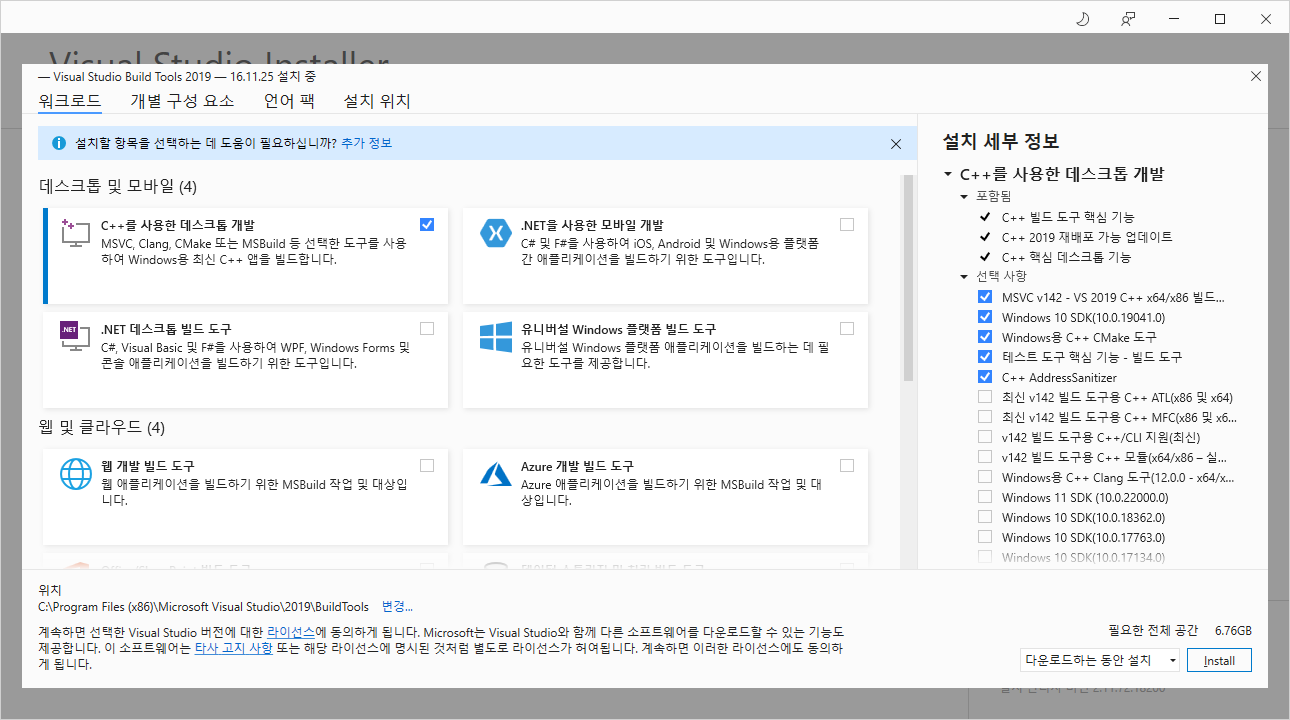
2. Visual Studio 2019 빌드 도구 다운로드 및 설치
최신 BuildTools 링크를 클릭하고 설치할 때, ++를 사용한 데스크탑 개발 환경을 선택
https://learn.microsoft.com/en-us/visualstudio/releases/2019/history#release-dates-and-build-numbers
Visual Studio 2019 build numbers and release dates
A list of released versions, build numbers, and release links for Visual Studio 2019.
learn.microsoft.com

(제일 아래 부분에 에러가 뜨는 데 위 옵션과 관련된 것일지 모르겠다)
3. 가상환경 구성
윈도우버튼 - 아나콘다 - 아나콘다 파워쉘(관리자 권한으로..maybe)

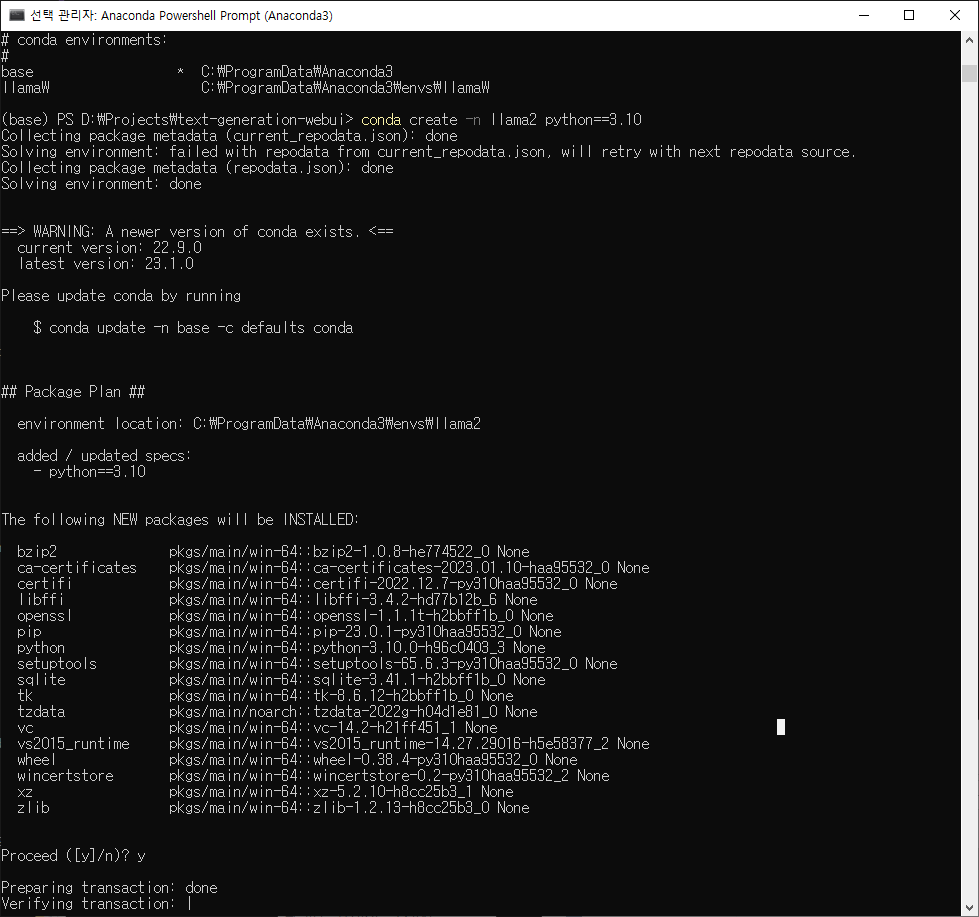
실행된 터미널에서 아나콘다를 활용해 가상환경을 만드는 명령은 $conda create -n (가상환경명) 이다. 뒤에 파이썬 버전을 붙이면 그 버전 파이썬이 설치된 가상환경이 만들어진다. 오픈소스로 움직이는 리눅스 생태계 특성상 딥러닝 환경을 구성할 때 다양한 에러가 생기는데 이것을 가상환경을 새로 만듦으로 깔끔히 해결할 수 있다.
$conda create -n llamaW python==3.10
파이썬 3.10을 설치한 가상환경생성
$conda activate llamaW
진입
$python
파이썬 버전확인, 파이썬 실행 안될시 아나콘다 환경변수 에러해결참고 https://coding-kindergarten.tistory.com/152 굿!!
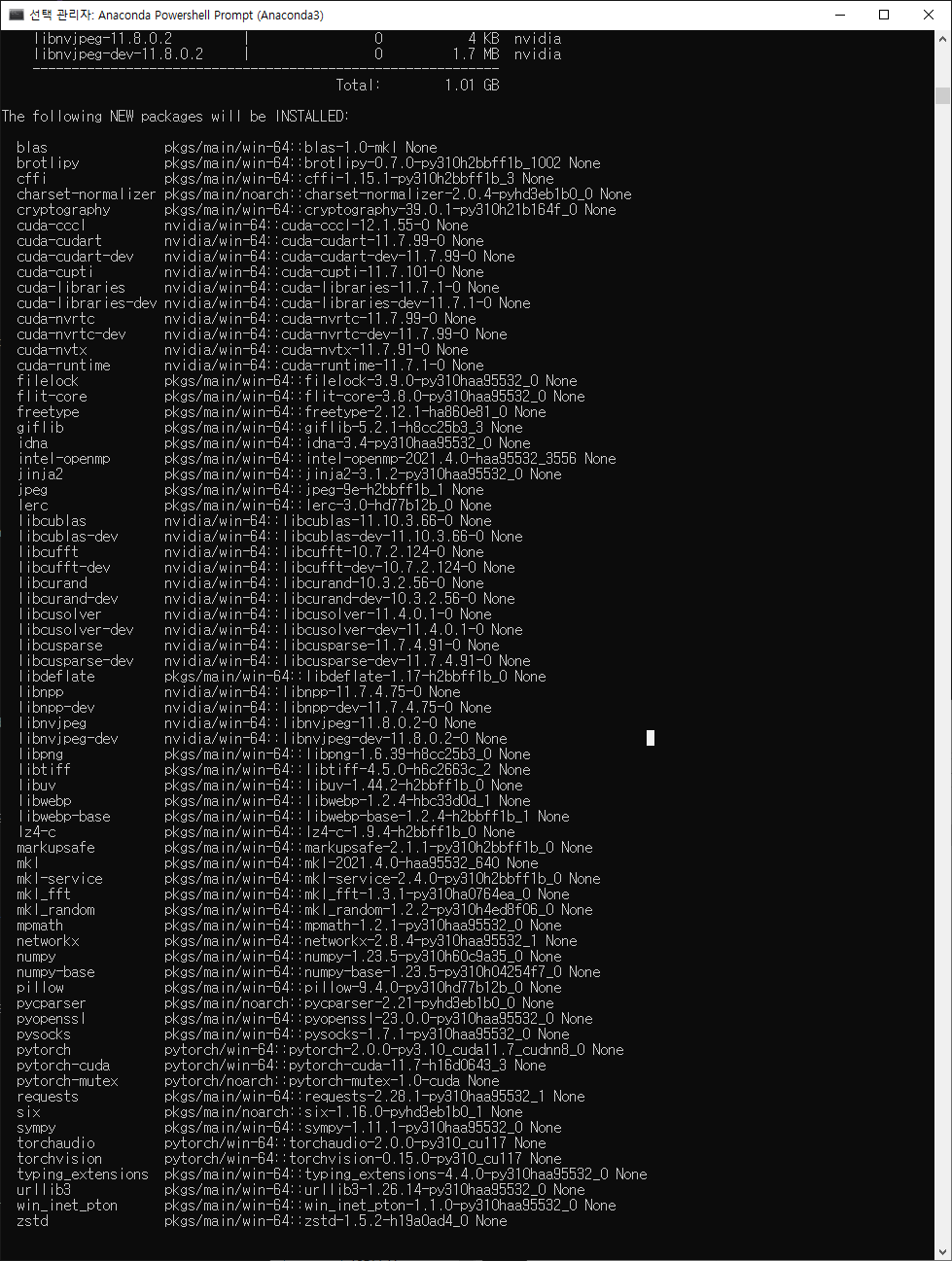
$conda install cuda pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia/label/cuda-11.7.0
쿠다, 파이토치와 관련 라이브러리 설치하기
시간도 걸리고 굉장히 많은 것들이 설치되는 모습을 캡쳐하고 싶었으나 어느덧 끝나고 정리된 프롬프트만..

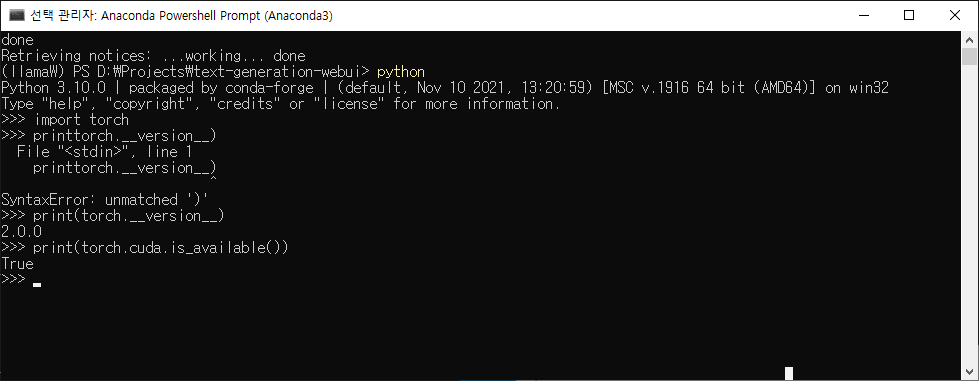
$python
파이썬 실행, 3.10버전 확인()
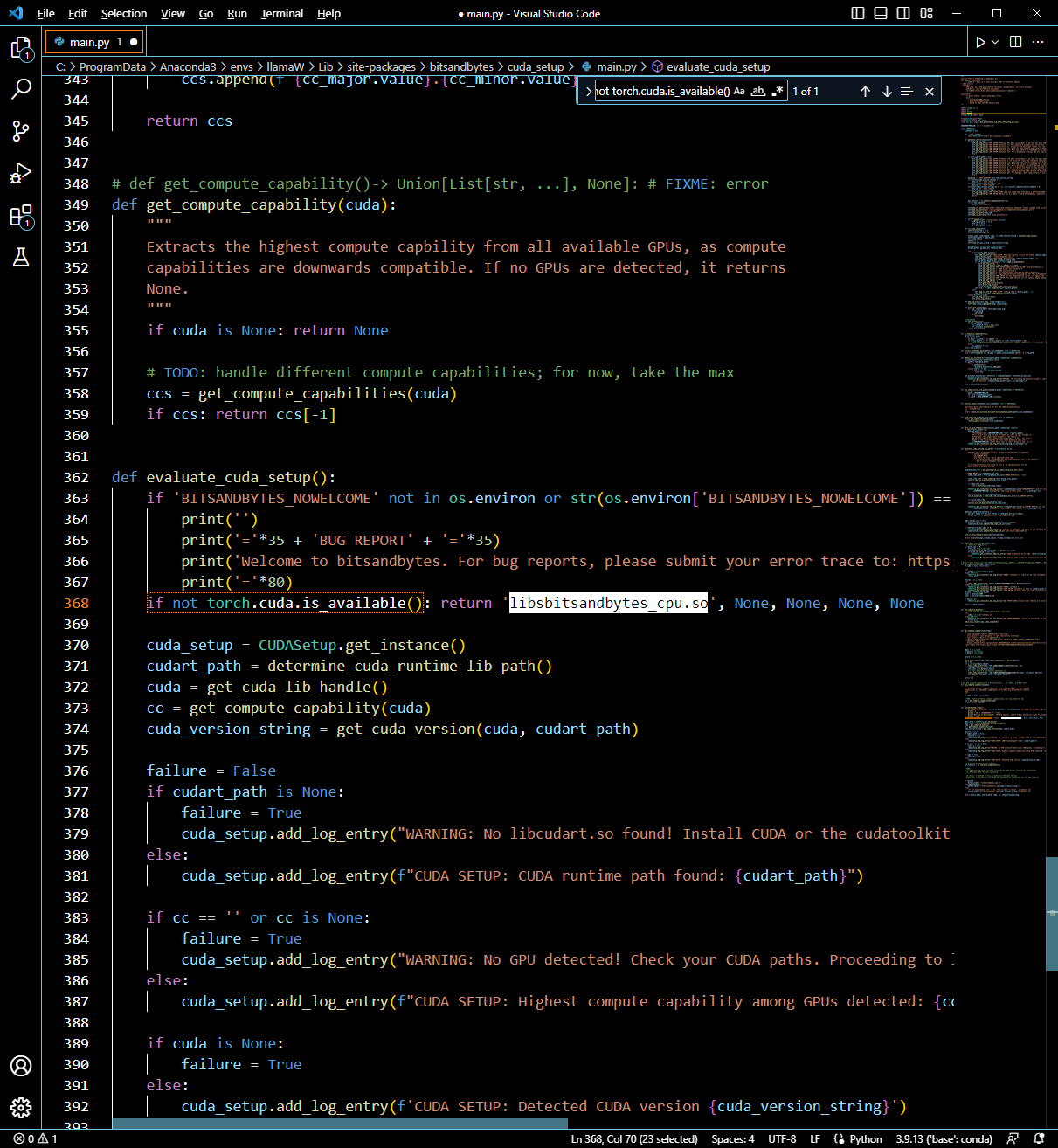
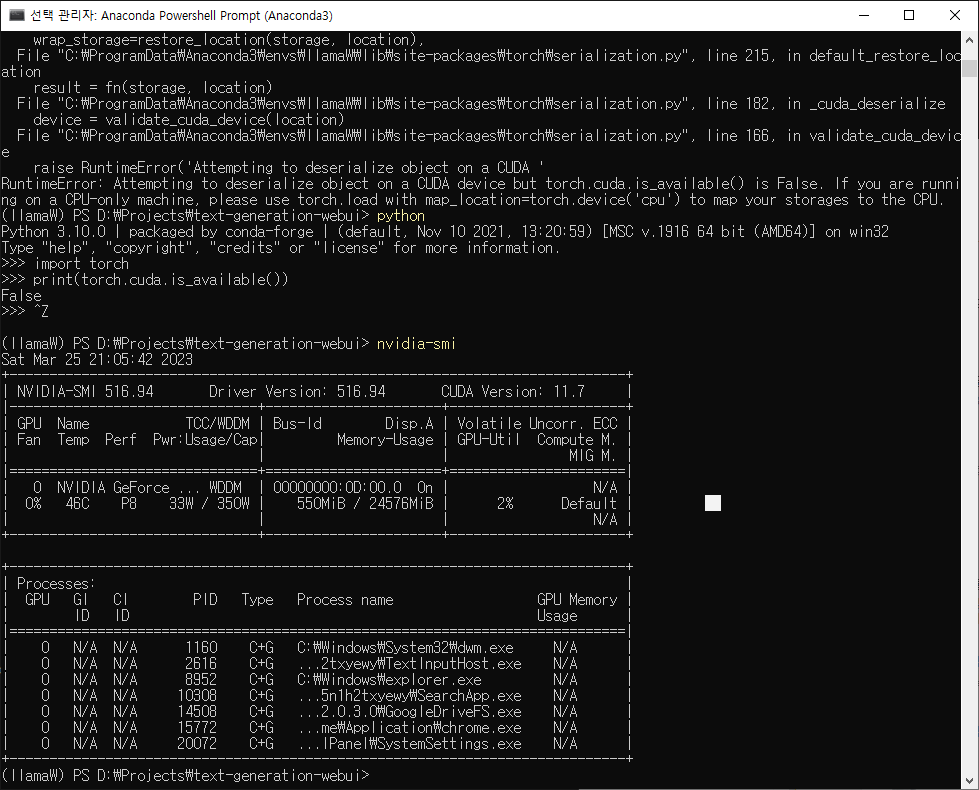
$import torch; print(torch.cuda.is_available())
파이토치를 불러와 쿠다를 사용할 수 있는지 물었고 True
$exit()
파이썬 종료

$pip install git
깃허브 레포지토리 다운을 위한 git 설치
$git clone https://github.com/oobabooga/text-generation-webui.git
깃을 이용해 text-generation-webui 다운 설치
$cd .\text-generation-webui\
$mkdir repositories
repositories란 디렉토리(폴더) 만듦
$cd .\repositories\
repositories 디렉토리로 이동
$git clone https://github.com/qwopqwop200/GPTQ-for-LLaMa.git
GitHub - qwopqwop200/GPTQ-for-LLaMa: 4 bits quantization of LLaMa using GPTQ
4 bits quantization of LLaMa using GPTQ. Contribute to qwopqwop200/GPTQ-for-LLaMa development by creating an account on GitHub.
github.com
$cd GPTQ-for-LLaMa
$pip install ninja
$python setup_cuda.py install
캡쳐하고 보니 아래에 에러가 떠있음. 워닝은 치명적인 문제가 아닌 경우가 많다는...
$cd ../..
$pip install -r requirements.txt
requirements.txt속 라이브러리 일괄 설치

$python download-model.py decapoda-research/llama-13b-hf
허깅페이스에서 llama-13b모델 다운(37.2기가바이트)
C드라이브 용량 부족으로 D로 옮겨 재도전
$python download-model.py decapoda-research/llama-30b-hf
바로 이어서 llama-30b 모델도 다운
$python .\server.py --cai-chat --load-in-4bit --model llama-13b --no-stream
실행하니 에러를 뿜는다. 머지.. 중간에 가상환경을 다시 만들었는디~ 일단 30b모델 다운받고 이어 쓰겠다.
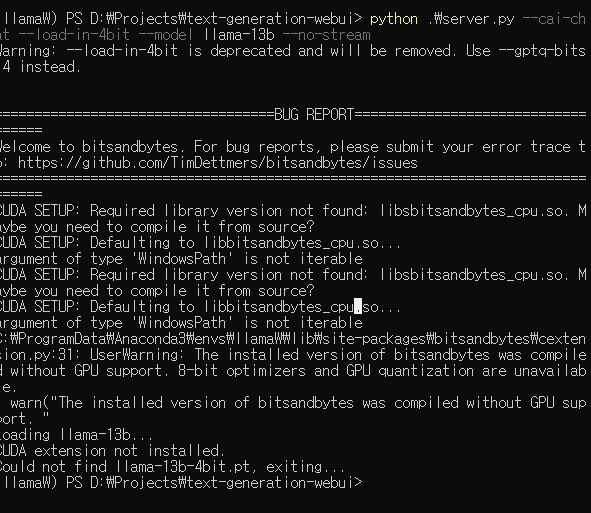
MS의 통합개발환경(IDE) 비주얼스튜디오에 대한 에러가 있는 것 같다.
<1차 작성이 여기까지,,, 30b모델 로드한 지금보니 쿠다툴킷, 쿠다라이브러리 설치 안해서 이럼>



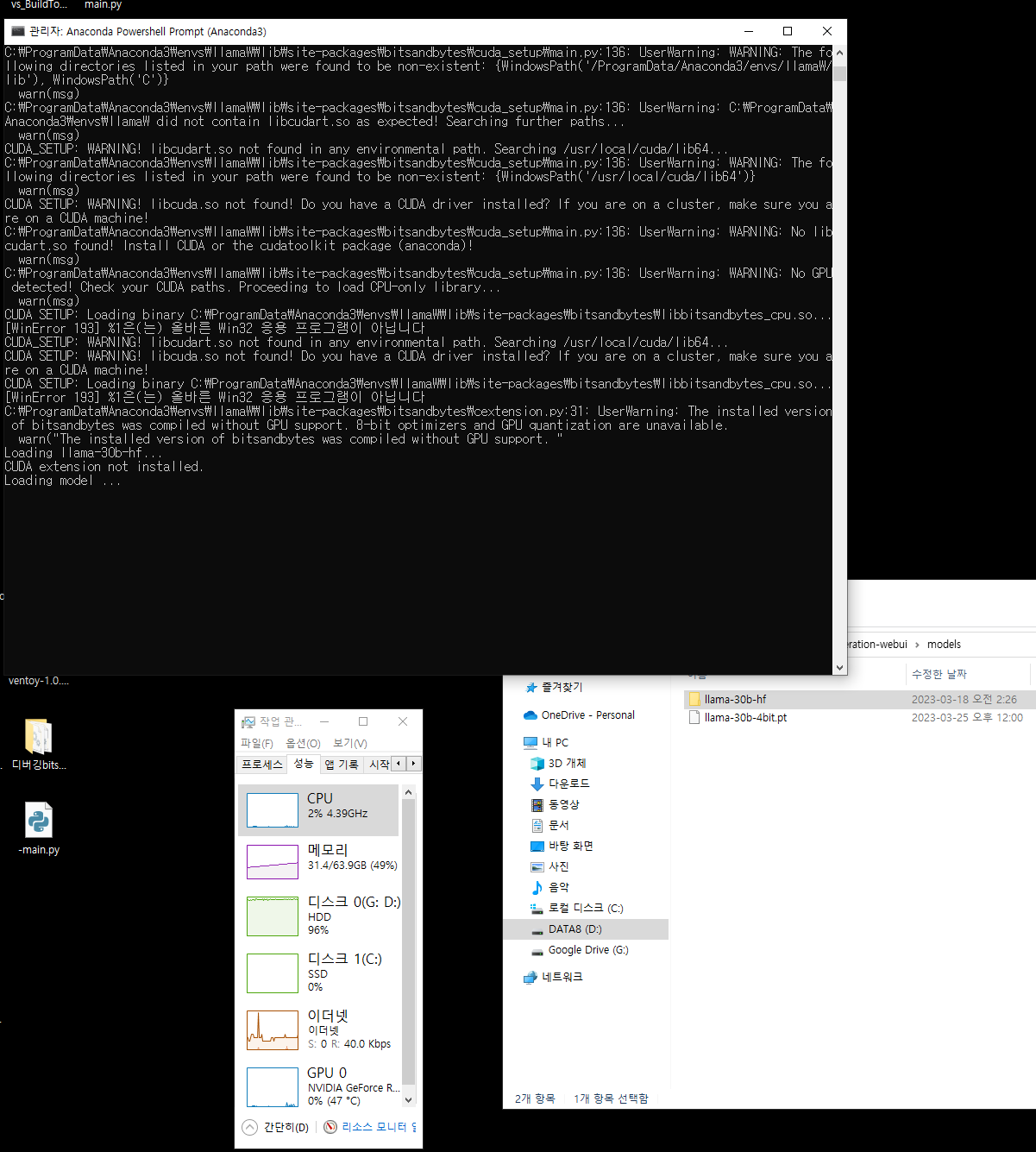



파이토치 다시 설치
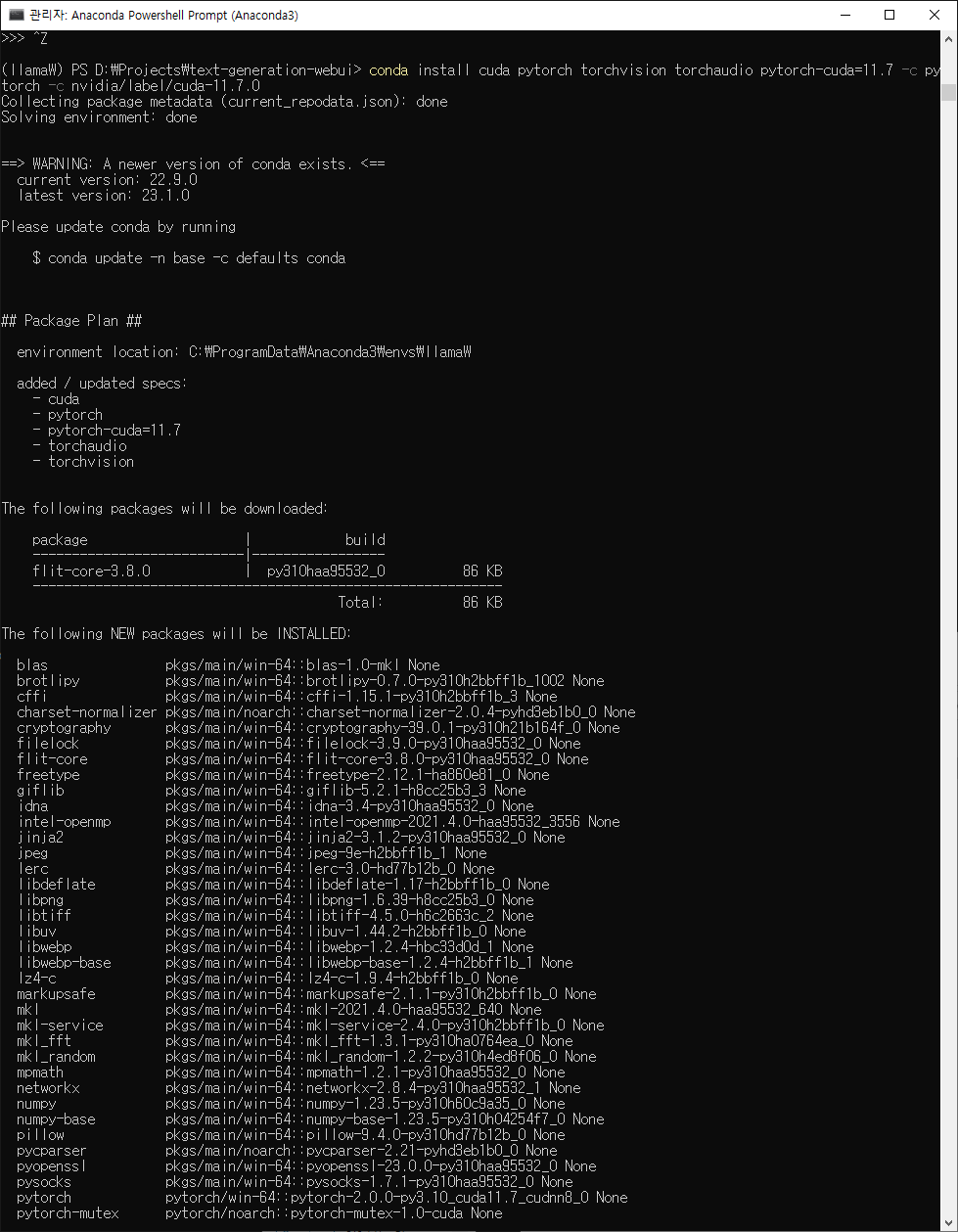

결국 새 환경 만듦
오픈소스는 역시 버전이 중요하다
토치2.0 쿠다 11.7
관련 종속라이브러리 설치
$pip install gradio
$pip install markdown
$pip install transformers
$pip install accelerate
$pip install peft


(llama2) PS D:\Projects\text-generation-webui> python .\server.py --load-in-4bit
Warning: --load-in-4bit is deprecated and will be removed. Use --gptq-bits 4 instead.
Loading llama-30b-hf...
CUDA extension not installed.
Traceback (most recent call last):
File "D:\Projects\text-generation-webui\server.py", line 236, in <module>
shared.model, shared.tokenizer = load_model(shared.model_name)
File "D:\Projects\text-generation-webui\modules\models.py", line 95, in load_model
model = load_quantized(model_name)
File "D:\Projects\text-generation-webui\modules\GPTQ_loader.py", line 55, in load_quantized
model = load_quant(str(path_to_model), str(pt_path), shared.args.gptq_bits)
File "D:\Projects\text-generation-webui\repositories\GPTQ-for-LLaMa\llama.py", line 220, in load_quant
from transformers import LlamaConfig, LlamaForCausalLM
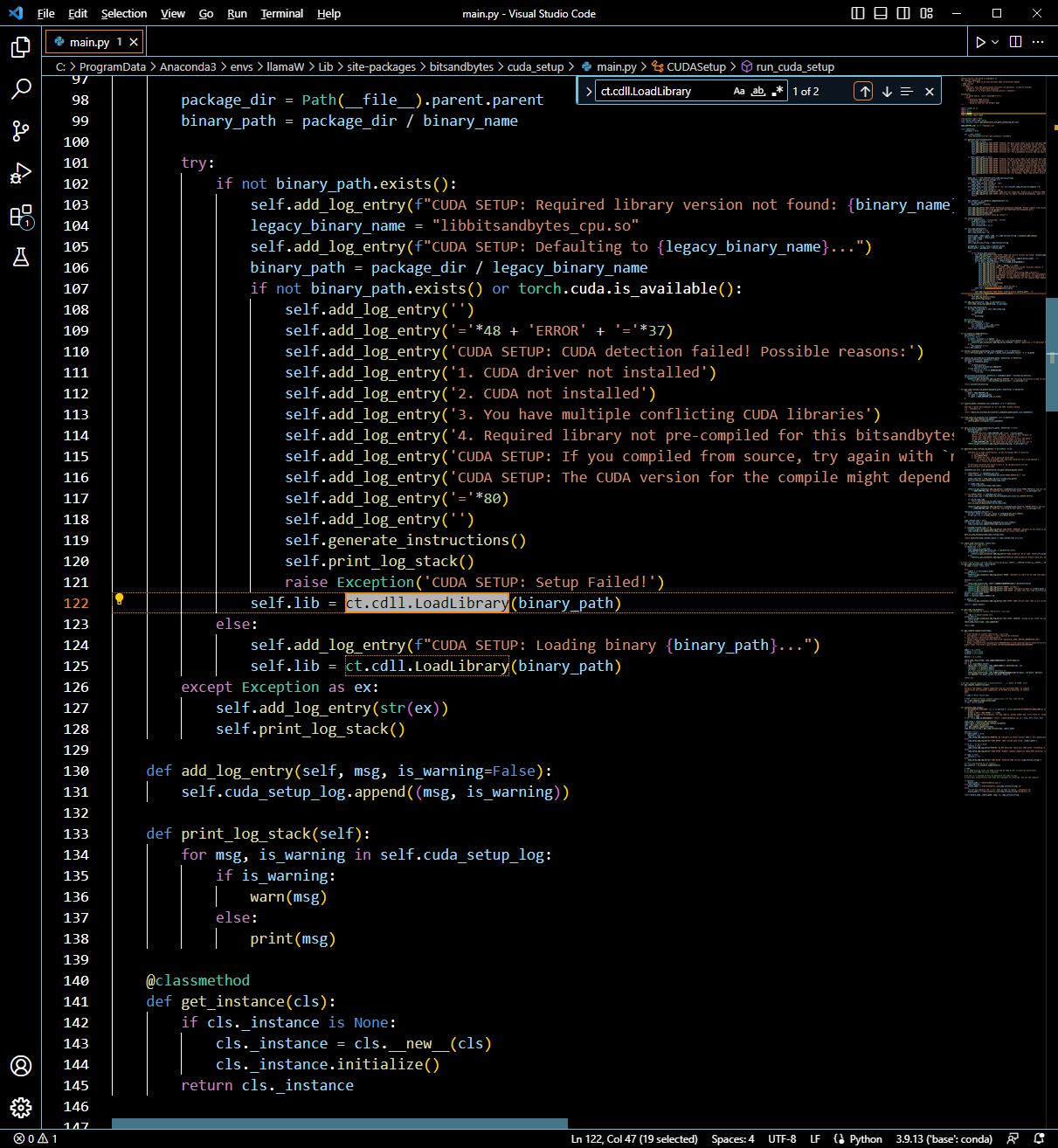
ImportError: cannot import name 'LlamaConfig' from 'transformers' (C:\ProgramData\Anaconda3\envs\llama2\lib\site-packages\transformers\__init__.py)여기에서 파이토치 버전이 1.13.1 cpu버전으로 바뀐다
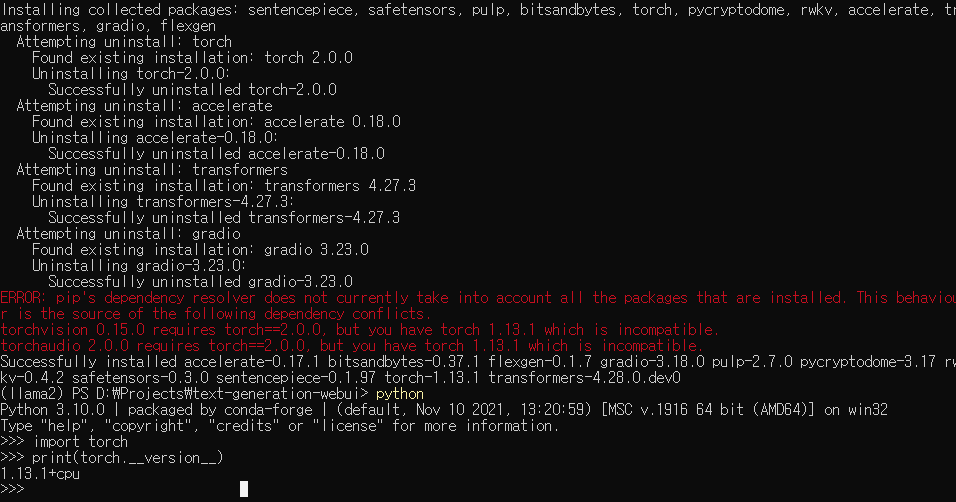

New ENV
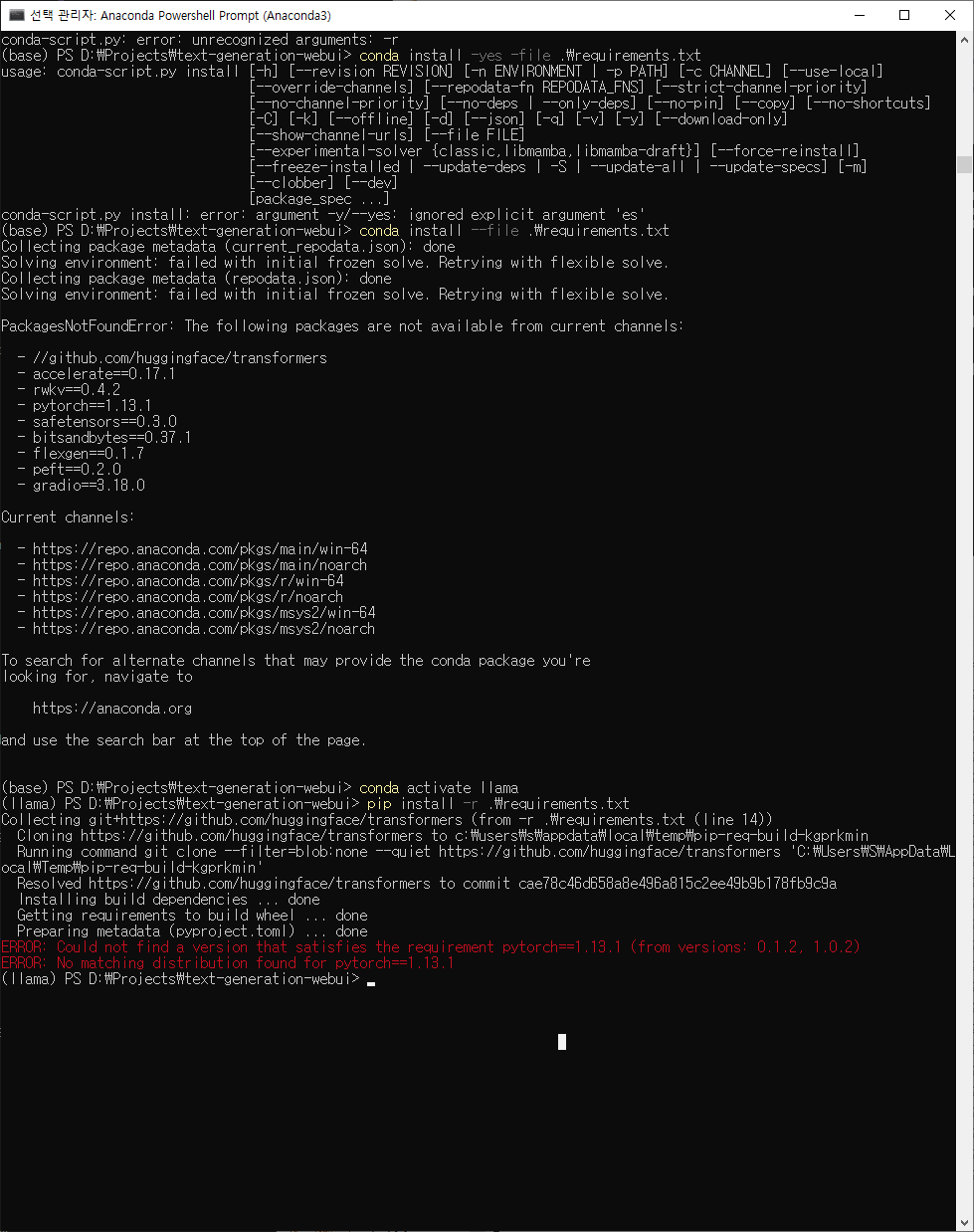
pytorch버전을 1.13.1로 정하고 설치
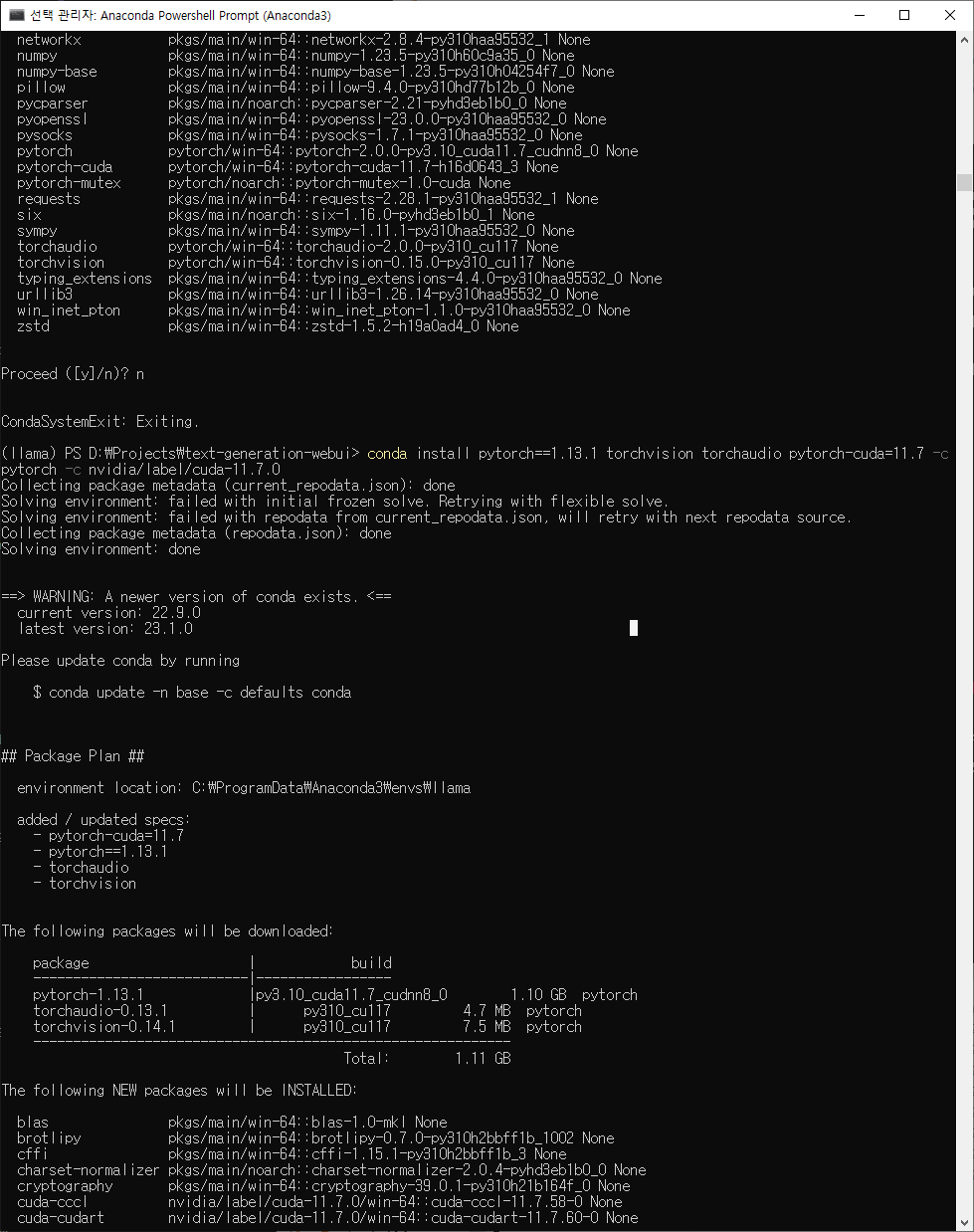
빙고!!

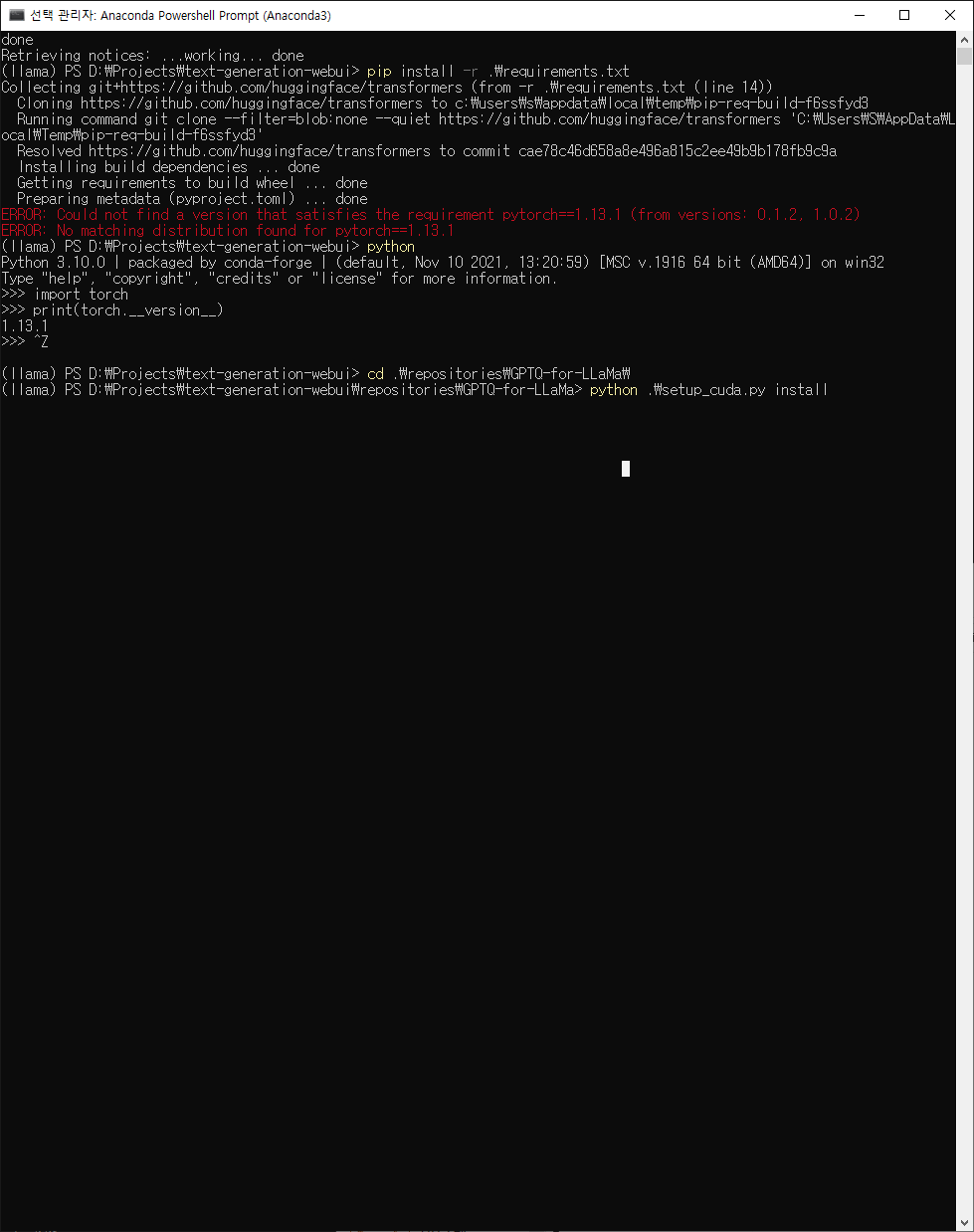
GPTQ 셋업 에러(아마 호환 버전에 따른) 후 없다는 라이브러리 설치
(llama) PS D:\Projects\text-generation-webui> python .\server.py --load-in-4bit
Warning: --load-in-4bit is deprecated and will be removed. Use --gptq-bits 4 instead.
Traceback (most recent call last):
File "D:\Projects\text-generation-webui\server.py", line 13, in <module>
import modules.chat as chat
File "D:\Projects\text-generation-webui\modules\chat.py", line 15, in <module>
from modules.text_generation import (encode, generate_reply,
File "D:\Projects\text-generation-webui\modules\text_generation.py", line 14, in <module>
from modules.models import local_rank
File "D:\Projects\text-generation-webui\modules\models.py", line 11, in <module>
from transformers import (AutoConfig, AutoModelForCausalLM, AutoTokenizer,
ImportError: cannot import name 'BitsAndBytesConfig' from 'transformers' (C:\ProgramData\Anaconda3\envs\llama\lib\site-packages\transformers\__init__.py)
(llama) PS D:\Projects\text-generation-webui>pip install transformers==4.21.2 해결 안됨
구글링하다 허깅페이스서 트랜스포머 설치
pip install git+https://github.com/huggingface/transformers성공하는 줄 알았으나, 에러
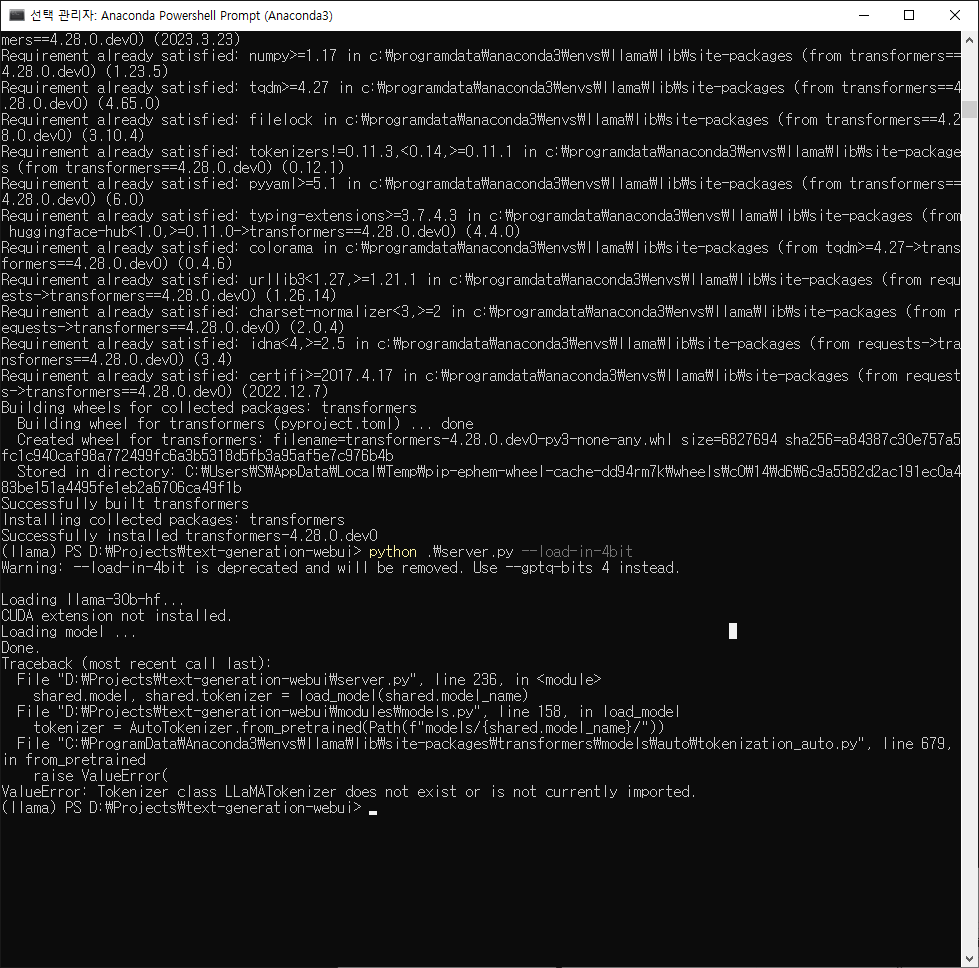
힌트 획득!!
안녕@candowu, 이 문제를 제기해 주셔서 감사합니다. 이는 허브의 구성에서tokenizer 가 를 가리키기 때문에 발생합니다 . 그러나 라이브러리의 토크나이저는 .LLaMATokenizerLlamaTokenizer
이는 최종 PR이 병합되기 전에 구성 파일이 생성되었기 때문일 수 있습니다.
tokenizer_config.json의 LLaMATokenizer를 소문자 LlamaTokenizer 로 변경하면 매력처럼 작동합니다.

13b모델 성공

30b모델 로드

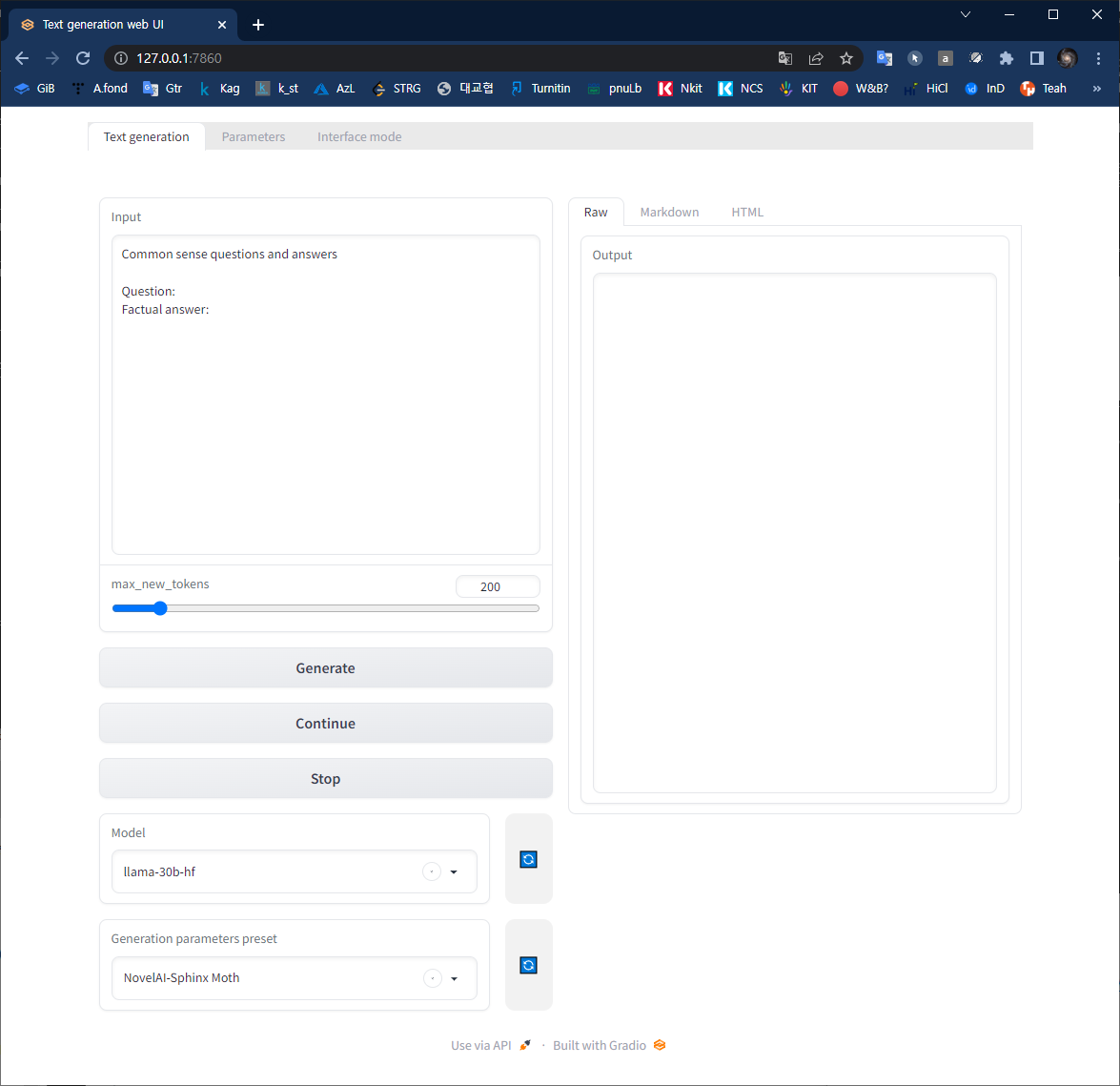
질문에 알맞는 답을 생성하려는데 에러가 난다. 다시금 생각하니 기본 중의 기본을 안했구나..
삽질은 일단 여기까지 하고~
여유가 생기면 쿠다 툴킷과 cuDNN 라이브러리를 설치하고 결과를 올리겠다. 모든 분 즐거운 개발하십시오!!
참고
https://gist.github.com/lxe/82eb87db25fdb75b92fa18a6d494ee3c
'Dev LLM' 카테고리의 다른 글
Ubuntu에서 CUDA toolkit 버전 변경 & gcc (0) 2023.06.10 "We Have No Moat, And Neither Does OpenAI" (0) 2023.05.28