-
GPU와 엣지컴퓨팅기기 AI(딥러닝)연산성능 비교(2025-02-03)카테고리 없음 2025. 1. 16. 02:31
GPU AI(딥러닝) 연산 성능
모델 FP32 (TFLOPS) FP16 (TFLOPS) peak INT8 Tensor
(TOPS)
CUDA 코어 수 GPU
메모리
메모리 대역폭 (GB/s) TDP (W) 전력 효율 (TFLOPS/W) H200 SXM (3200?) 141GB HBM3e 4915 H100 SXM 67 1979 3958 16896 80GB HBM3 3430 700 A100 19.5 312 624 6912 80GB HBM2e 1935 300 GeForce RTX 5090 104.6 838 (1824?) 21760 32GB GDDR7 1536 575 0.182 GeForce RTX 5080 56.25 450 (1334?) 10752 16GB GDDR7 1152 360 0.156 GeForce RTX 5070Ti 43.75 352 (992?) 8960 16GB GDDR7 896 300 GeForce RTX 4090 82 1321 16384 24GB GDDR6X 1018 450 0.182 GeForce RTX 4080 49 780 9728 16GB GDDR6X 717 320 0.153 GeForce RTX 4070 Ti 40 641 7680 12GB GDDR6X 504 285 0.140 GeForce RTX 4070 31.25 466
(1,000?)5888 12GB GDDR6 504 250 0.140 GeForce RTX 3090 Ti 40 320 10752 24GB GDDR6X 936 350 0.114 GeForce RTX 3090 36 285 10496 24GB GDDR6X 936 350 0.103 GeForce RTX 3080 Ti 34 273 10240 12GB GDDR6X 912 350 0.106 GeForce RTX 3080 30 238 8704 10GB GDDR6X 760 320 0.094 GeForce RTX 3070 Ti 22 178.4 6144 8GB GDDR6X 608 290 0.076 GeForce RTX 3070 20 162.4 5888 8GB GDDR6 448 220 0.091 NVIDIA GeForce RTX 3060 Ti 16 4864 8GB GDDR6 448 200 0.080 NVIDIA Titan RTX 16 4608 24GB GDDR6 672 280 0.057 NVIDIA GeForce RTX 2080 Ti 13 4352 11GB GDDR6 616 250 0.052 NVIDIA GeForce RTX 2080 10 2944 8GB GDDR6 448 215 0.047 NVIDIA GeForce RTX 2070 7.5 2304 8GB GDDR6 448 175 0.043 NVIDIA GeForce GTX 1080 Ti 11.3 3584 11GB GDDR5X 484 250 0.045 NVIDIA GeForce GTX 1080 8.9 2560 8GB GDDR5X 320 180 0.049 GeForce RTX 1660 Ti 5.5 1536 6GB GDDR6 288 120 0.046 GeForce RTX 1660 Super 5.2 1408 6GB GDDR6 336 125 0.042 GeForce RTX 1660 4.4 1408 6GB GDDR5 192 120 0.037 GeForce RTX 1650 Super 4 1280 4GB GDDR6 192 100 0.040 GeForce RTX 1650 3.9 896 4GB GDDR5 128 75 0.052 엣지디바이스 딥러닝 연산 성능(2025.01.16.)
*값은 완전 이상적인 환경에서 얻어낸 값 같습니다. 참고만 하세요.
모델 FP16
(TFLOPS)
Tensor core
FP16 (TFLOPS)
CUDA
core
FP16 (TFLOPS)
INT8 (TOPS) CUDA 코어 수 메모리 메모리 대역폭 (GB/s) TDP (W) Jetson AGX Orin 64GB 10.65 *85 *10.65 275 2048 64GB LPDDR5 204.8GB/s 15-60 Jetson AGX Orin 32GB 6.73 *54 *6.73 200 1792 32GB LPDDR5 204.8GB/s 15-40 Jetson Orin NX 16GB Super 157 1024 16GB LPDDR5 102.4GB/s 10-40 Jetson Orin NX 16GB 3.76 100 1024 16GB LPDDR5 102.4GB/s 10-25 Jetson Orin NX 8GB Super 117 1024 8GB LPDDR5 N/A 10-40 Jetson Orin NX 8GB 3.12 70 1024 8GB LPDDR5 N/A 10-25 Jetson Orin Nano 8GB Super 67 1024 8GB LPDDR5 N/A 7-25 Jetson Orin Nano 8GB 40 1024 8GB LPDDR5 N/A 7-10 Jetson Orin Nano 4GB Super 34 1024 4GB LPDDR5 N/A 7-25 Jetson Orin Nano 4GB 20 512 4GB LPDDR5 N/A 7-10 Jetson AGX Xavier 32/64GB 32 512 32/64GB LPDDR4x N/A 30 Jetson Xavier NX 6 21 384 16GB LPDDR4x N/A 15 Jetson Nano 4GB 5 128 4GB LPDDR5 N/A 5-10 Benchmark on RPi5 & CM4 running yolov8s with Hailo 8L

라즈베리파이5에 Halio8 가속기를 적용한 결과입니다.
참고자료
https://www.nextplatform.com/2022/03/31/deep-dive-into-nvidias-hopper-gpu-architecture/
Deep Dive Into Nvidia’s “Hopper” GPU Architecture
With each passing generation of GPU accelerator engines from Nvidia, machine learning drives more and more of the architectural choices and changes and
www.nextplatform.com
https://developer.nvidia.com/embedded/jetson-benchmarks
Jetson Benchmarks
Gen AI Benchmarks NVIDIA Jetson AI Lab is a collection of tutorials showing how to run optimized models on NVIDIA Jetson, including the latest generative AI and transformer models. These tutorials span a variety of model modalities like LLMs (for text), VL
developer.nvidia.com
https://developer.download.nvidia.com/403.html?__token__=exp%3D1736959685~hmac%3D5942dffcbb43d71affa4ecff5edda5b41b2d5f61f936ccdbe14debbab94ea8a6
developer.download.nvidia.com
https://developer.download.nvidia.com/403.html?__token__=exp%3D1736962268~hmac%3Dc09fd7ac3030f0dfc2edfa4a85d907415f663ec90306255984e44530af17f904&t=eyJscyI6InJlZiIsImxzZCI6IlJFRi1qc3RhcjA1MjUudGlzdG9yeS5jb20vNTcifQ%3D%3D
developer.download.nvidia.com

250110 젯슨 오린 ** 슈퍼 업데이트 추가 https://lambdalabs.com/blog/nvidia-rtx-4090-vs-rtx-3090-deep-learning-benchmark
NVIDIA GeForce RTX 4090 vs RTX 3090 Deep Learning Benchmark
RTX 4090 vs RTX 3090 benchmarks to assess deep learning training performance, including training throughput/$, throughput/watt, and multi-GPU scaling.
lambdalabs.com
https://concurrency.tistory.com/22
최신 GPU Spec 체크
RTX 4090 Ada Lovelace와 Ampere의 가장 큰 차이점은 몰까? CUDA Core의 수가 꽤 많이 증가했다. 그리고 Tensor Cores의 수와 버전도 올라가고. 연산능력이 3090비해 두배 늘어났네! 특이한점은 FP8에 대한 연산능
concurrency.tistory.com
https://www.tomshardware.com/reviews/nvidia-geforce-rtx-4090-review
Nvidia GeForce RTX 4090 Review: Queen of the Castle
Ada Lovelace delivers the goods, at a steep price.
www.tomshardware.com
https://forums.raspberrypi.com/viewtopic.php?t=373867&sid=691dcb3abefea8284e2e84a4aa036b19
Benchmark on RPi5 & CM4 running yolov8s with Hailo 8L - Raspberry Pi Forums
Mon Jul 22, 2024 3:54 am Ainsfei wrote: ↑Thu Jul 18, 2024 10:44 am Hello everyone, we are a team from Seeed Studio. Recently, we have tested two demos of YoloV8s on Pi5 and CM4, using Hailo 8L for acceleration. We have measured parameters such as frame r
forums.raspberrypi.com
https://wiki.seeedstudio.com/benchmark_on_rpi5_and_cm4_running_yolov8s_with_rpi_ai_kit/
Benchmark on RPi5 and CM4 running yolov8s with rpi ai kit | Seeed Studio Wiki
This wiki demonstrates yolov8s pose estimation and object detection benchmark on Raspberry Pi5 and Raspberry Pi Compute Module 4.
wiki.seeedstudio.com


Jetson AGX Xavier, Jetson AGX Orin 64gb의 성능비교 
https://developer.nvidia.com/embedded/jetson-benchmarks
[Jetson Benchmarks
Jetson is used to deploy a wide range of popular DNN models and ML frameworks to the edge with high performance inferencing, for tasks like real-time classification and object detection, pose estimation, semantic segmentation, and natural language processi
developer.nvidia.com](https://developer.nvidia.com/embedded/jetson-benchmarks)
https://developer.nvidia.com/embedded/jetson-modules
[Jetson Modules, Support, Ecosystem, and Lineup
Build and manage edge AI, and deploy innovative products.
developer.nvidia.com](https://developer.nvidia.com/embedded/jetson-modules)
TFlops (테라플롭스)는 초당 1조 번의 부동 소수점 연산을 나타내며, TOPs는 텐서 연산을 기준으로 합니다. 텐서 연산의 정의와 TFlops와의 직접적인 변환 비율은 구체적인 하드웨어 및 연산 유형에 따라 다릅니다. GPU나 AI 프로세서는 특정 종류의 텐서 연산을 위해 최적화되어 있으며, 이러한 장치에서는 TFlops와 TOPs 간의 변환 비율이 명확하게 정의되지만, 하드웨어 사양과 연산 유형에 따라 달라집니다.
NVIDIA GPU 모델 TensorFLOPS (또는 최대 DL 성능) 지포스 GTX 타이탄 X 맥스웰 N/A TensorTFLOPS ~6.1TFLOPS FP32 지포스 GTX 1080 Ti N/A 텐서 TFLOPS ~11.3 TFLOPS FP32 지포스 타이탄 XP N/A 텐서 TFLOPS ~12.1 TFLOPS FP32 지포스 타이탄 V 110 텐서TFLOPS 지포스 RTX 2080 Ti 56.9 TensorTFLOPS 455.4 추론용 TOPS INT4 타이탄 RTX 추론용 TensorTFLOPS 520 TOPS INT4 130개 테슬라 K80 N/A 텐서 TFLOPS 5.6 TFLOPS FP32 테슬라 P100* 해당 없음 텐서 TFLOPS 18.7 ~ 21.2 TFLOPS FP16 쿼드로 GP100 N/A 텐서 TFLOPS 20.7 TFLOPS FP16 테슬라 V100* 112 ~ 125 텐서TFLOPS 쿼드로 GV100 118.5 텐서TFLOPS 쿼드로 RTX 6000 및 8000 130.5 추론용 TensorTFLOPS 522 TOPS INT4 테슬라 T4 추론용 TensorTFLOPS 260 TOPS INT4 65개 엔비디아 A100 추론용 312 FP16 TensorTFLOPS 1248 TOPS INT4 대략 GTX 970 < Jetson-Xaiver < 1060 < 1080 < P100
참고 https://hwinfo.tistory.com/20
Nvida H100 SXM : 67 TFlops (FP32) Nvida H100 PCIe : 51 TFlops (FP32) RTX 4090 : 90 TFlops (2022.09)**
RTX A6000** : 38.7 TFlops RTX 3090 : 35.7 TFlops (2020.09) RTX 3080Ti : 34.1 TFlops
RTX 3080 : 29.7 TFlops RTX 3070Ti : 21.7 TFlops RTX 3070 : 20.3 TFlopsRTX 3060Ti : 16.2 TFlops RTX 3060 : 12.7 TFlops **RTX A100** : 19.5 TFlops
**RTX 2080** : 11.14 TFlops GTX 1080Ti : 11.3 TFlops (2017.03) **GTX 1080** : 9.0 TFlops
**GTX 1070** : 6.5 TFlops **GTX 1660** : 5.0 TFlops **GTX 1060** : 3.9 TFlops **GTX 960** : 2.4 TFlopsXBOX Series X : 12.15 TFlops XBOX Series S : 4.0 TFlops
PS5 : 10.28 TFlops PS4 pro : 4.2 TFlops PS4 : 1.84 TFlopsApple M1 (GPU) : 2.6 TFlops
**Google Tpu v1 :** 23 TFlops - 2015 Google Tpu v2 : 45 TFlops - 2017
Google Tpu v3 : 140 TFlops - 2018 Google Tpu v4 : 244 TFlops(Tpu v4를 1024개 묶어 하나의 pod로) - 2020
Google Edge TPU (Coral, 2019) : 4 TFlopsLightmatter envise : 90 TFlops (세계최초의 양산형 광자컴퓨터 / 추정치)
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
FLOPS(FLoating point OPerations per Second)
kFLOPS (kiloFLOPS, 10^3)
MFLOPS (MegaFLOPS, 10^6)
GFLOPS (GigaFLOPS, 10^9)
TFLOPS (TeraFLOPS, 10^12) : 1초에 1조번 연산
PFLOPS (PetaFLOPS, 10^15) : 1초에 1,000조번 연산
EFLOPS (ExsaFLOPS, 10^18) : 구글 Tpu V4 를 4096개 묶어서 1엑사 플롭스 성능 달성GPU NVIDIA H100-PCIE NVIDIA A100-PCIE Geforce RTX4090 Geforce RTX 3090 아키텍처 Hopper Ampere Ada Lavelace Ampere GPU 기반 클럭 990 MHz 765 MHz GPU Boost 시간 시계 1755 MHz 1410 MHz 2520 MHz 1695 MHz CUDA 코어 수 14592 6912 16384 10496 TensorCore 수 456 432 512 328 메모리 사양 HBM2e HBM2e GDDR6X GDDR6X 메모리 인터페이스 5120비트 5120비트 384비트 384비트 메모리 대역 2000 GB/sec 1935 GB/sec 1008 GB/sec 936 GB/sec 메모리 용량 80GB 80GB 24GB 24GB 최대 소비 전력 350W 300W 450W 350W FP64 이론 성능 48 TFLOPS 9.7 TFLOPS FP32 이론 성능 48 TFLOPS 19.5 TFLOPS 82.6 TFLOPS 35.6 TFLOPS FP16 이론 성능 96 TFLOPS 78 TFLOPS 82.6 TFLOPS 35.6 TFLOPS TensorCore FP64 이론성능 48 TFLOPS 19.5 TFLOPS TensorCore FP16 이론성능 (희소성 기능) 800 TFLOPS (1600 TFLOPS) 312 TFLOPS (624 TFLOPS) 330.3 TFLOPS (660.6 TFLOPS) 142 TFLOPS (284 TFLOPS) TensorCore TF32 이론성능 (희소성 기능) 400 TFLOPS (800 TFLOPS) 156 TFLOPS (312 TFLOS) 82.6 TFLOPS (165.2TFLOPS) 35.6 TFLOPS (71 TFLOPS) TensorCore FP8 이론성능 (희소성 기능) 1600 TFLOPS (3200 TFLOPS) 660 TFLOPS (1321.2 TFLOPS) 
1,000,000,000 FLOPS = 1 GFLOPS(giga FLOPS), 1000 GFLOPS = 1 TFLOPS (Tera FLOPS)
위 그림 중 Xavier는 Jetson agx Xavier를 의미합니다. Ni는 기준점으로, 젯슨나노성능을 1로 잡은 제가 만든 단위입니다.
FP32과 INT8, Quantization: Quantization은 실수형 변수(floating-point type)를 정수형 변수(integer or fixed point)로 변환하는 과정을 뜻합니다.

- 예를 들어 위 그림과 같이 Quantization을 적용하면 일반적으로 많이 사용하는 FP32 타입의 파라미터를 INT8 형태로 변환한 다음에 실제 inference를 하게됩니다.
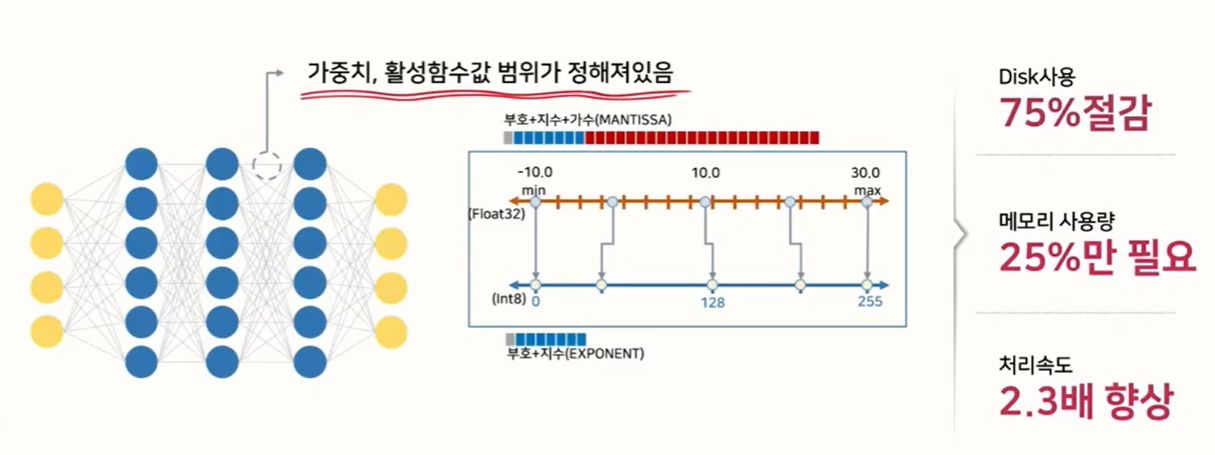
- 이 작업은 weight나 activation function의 값이 어느 정도의 범위 안에 있다는 것을 가정하여 이루어 지는 모델 경량화 방법입니다.
- 위 그림과 같이 floating point로 학습한 모델의 weight 값이 -10 ~ 30 의 범위에 있다고 가정하겠습니다. 이 때, 최소값인 -10을 uint8의 0에 대응시키고 30을 uint8의 최대값인 255에 대응시켜서 사용한다면 32bit 자료형이 8bit 자료형으로 줄어들기 때문에 전체 메모리 사용량 및 수행 속도가 감소하는 효과를 얻을 수 있습니다.
- 이와 같이 Quantization을 통하여 효과적인 모델 최적화를 할 수 있는데, float 타입을 int형으로 줄이면서 용량을 줄일 수 있고 bit 수를 줄임으로써 계산 복잡도도 줄일 수 있기 때문입니다. (일반적으로 정수형 변수의 bit 수를 N배 줄이면 곱셈 복잡도는 N*N배로 줄어듭니다.)
- 또한 정수형이 하드웨어에 좀 더 친화적인 이유도 있기 때문에 Quantization을 통한 최적화가 필요합니다.
- 정리하면 ① 모델의 사이즈 축소, ② 모델의 연산량 감소, ③ 효율적인 하드웨어 사용이 Quantization의 주요 목적이라고 말할 수 있습니다.
- [딥러닝의 Quantization (양자화)와 Quantization Aware Training
gaussian37's blog
gaussian37.github.io](https://gaussian37.github.io/dl-concept-quantization/)
참조 https://gaussian37.github.io/dl-concept-quantization/


*위 내용은 제조사 데이터시트, 블로그, 기사를 토대로 수집한 내용입니다. 수정할 것 있으면 댓글 주세요~